为语音 Core 做贡献
贡献者可以通过两种方式提升语音核心:
- 改进文本转语音(TTS)模型
- 贡献新的语音数据
由于语音识别(STT)模型目前使用的是 Azure 服务,其准确性已经达到最佳状态,无需进一步改进,因此无需对 STT 模型进行贡献。
改进 TTS 模型
与模型相关的所有文件都必须提交。本生态系统支持多个服务提供商。以下是它们及其要求的列表:
- sovits.pth:这是您的主要模型文件。请确保按要求将其命名为 “sovits.pth”。
- reference1.wav:.wav 格式的参考音频文件。请确保文件名称与 “config.json” 文件中的引用名称一致。
- gpt.ckpt:模型的检查点文件。请确认其名称为 “gpt.ckpt”。
- config.json:模型的配置文件。其名称必须为 “config.json”。
以下是完整模型示例文件夹提交的结构:
AudioModelSubmission/
├── sovits.pth # 主要模型文件
├── reference1.wav # 参考音频文件(名称与 config.json 中一致)
├── gpt.ckpt # 模型的检查点文件
└── config.json # 模型的配置文件示例 config.json 文件内容如下:
{
"refFile": "Olyn.wav",
"refText": "yet still, I stand, a testiment to the resilience of human spirit"
}要提交语音模型,请选择 “Voice Core”。
然后选择 “I got a Voice Model”,并按照上述指南上传模型文件。
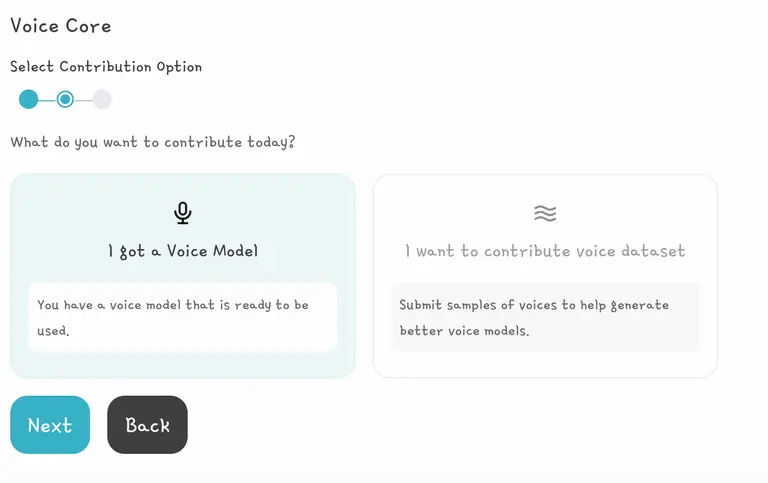
新语音数据贡献
- 提交的语音数据必须是合法获取且有权共享的。
- 获取的语音数据必须来自可靠的来源。
- 语音数据应无背景噪音,音频中仅保留要训练的语音。
- 语音数据必须以 .wav 格式生成。